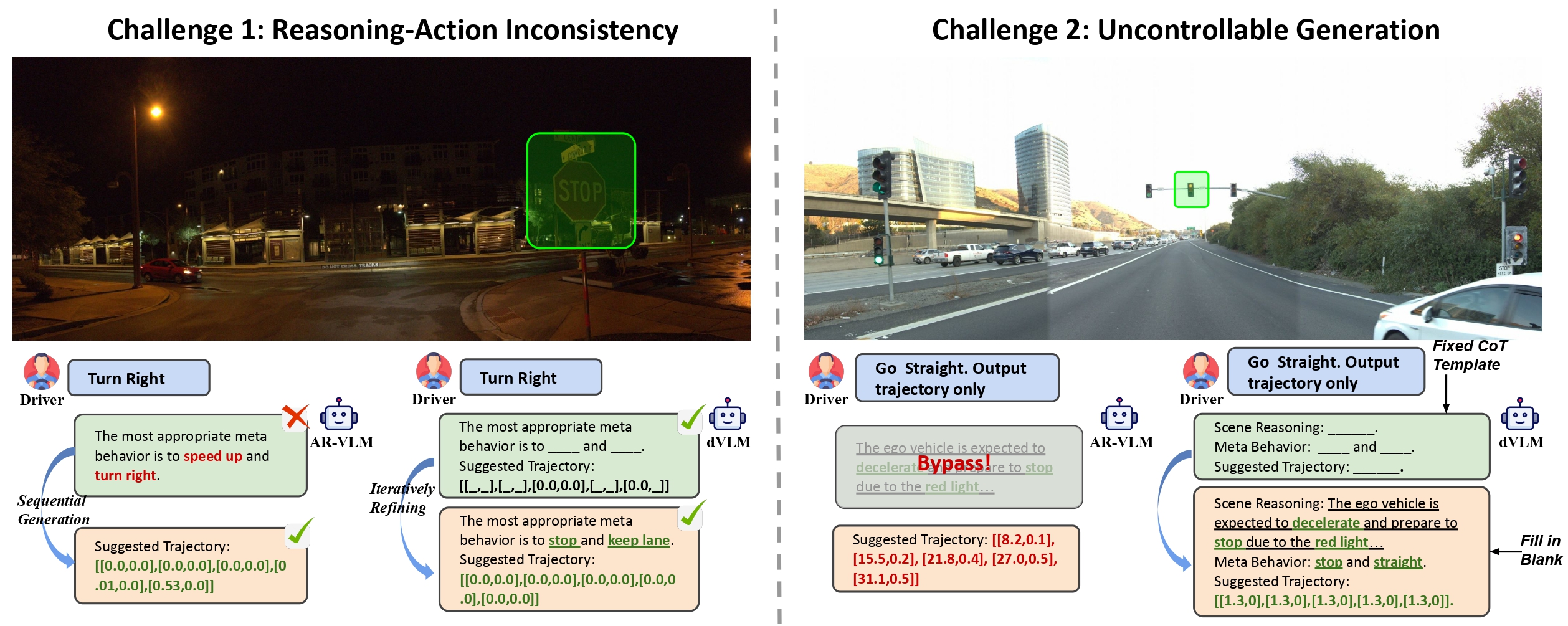
Challenge 1: Reasoning–Action Inconsistency:
the predicted trajectory often contradicts the model’s stated reasoning.
Challenge 2: Uncontrollable Generation:
structured reasoning can be bypassed or corrupted by prompt-level perturbations.
Abstract
The autonomous driving community is increasingly focused on addressing the challenges posed by out-of-distribution (OOD) driving scenarios.
A dominant research trend seeks to enhance end-to-end (E2E) driving systems by integrating vision–language models (VLMs), leveraging their rich world knowledge and reasoning abilities to improve generalization across diverse environments.
However, most existing VLMs or vision–language agents (VLAs) are built upon autoregressive (AR) models.
In this paper, we observe that existing AR-based VLMs—limited by causal attention and sequential token generation—often fail to maintain consistency and controllability between high-level reasoning and low-level planning.
In contrast, recent discrete diffusion VLMs equipped with bidirectional attention exhibit superior controllability and reliability through iterative denoising.
Building on these observations, we introduce dVLM-AD, a diffusion-based vision–language model that unifies perception, structured reasoning, and low-level planning for end-to-end driving.
Evaluated on nuScenes and WOD-E2E, dVLM-AD yields more consistent reasoning–action pairs and achieves planning performance comparable to existing driving VLM/VLA systems despite a modest backbone,
outperforming ARM-based baselines with a 9% improvement in behavior–trajectory consistency and a 6% increase in RFS on long-tail WOD-E2E scenarios.
These results suggest a controllable and reliable pathway for scalable end-to-end driving.
Our Approach
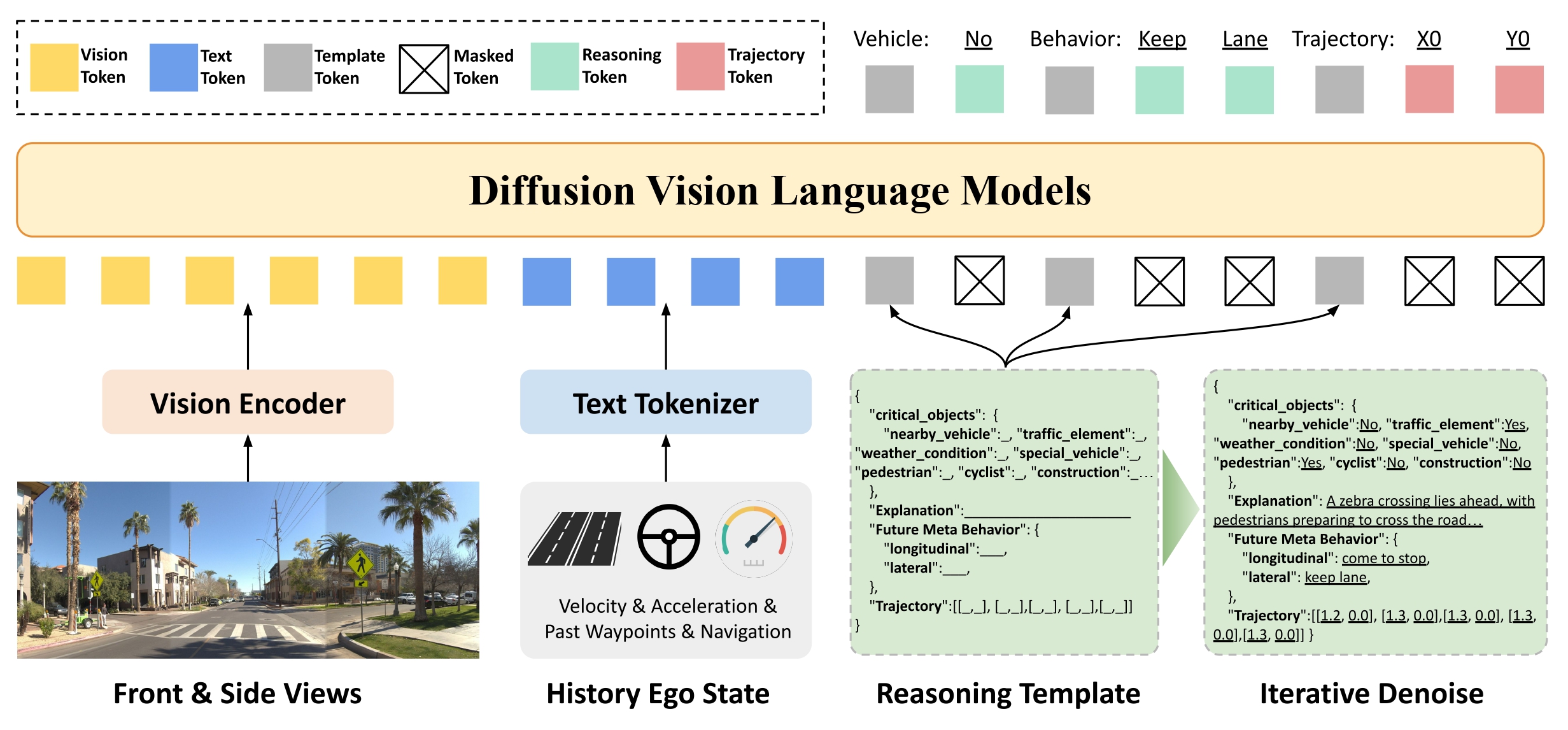
⚙️ Unified Diffusion-based Planner dVLM-AD starts from a structured chain-of-thought template that includes critical objects, causal explanations, future meta behavior, and a sequence of waypoints.
Instead of left-to-right decoding, a diffusion denoiser iteratively refines all reasoning and action tokens jointly, conditioned on multi-camera views, navigation commands, and ego state.
🧩 Controllable Structured Reasoning
During decoding, only editable slots in the template are masked and updated, so the schema itself enforces safety and format constraints.
A dynamic denoise strategy with a special reduce token allows variable-length phrases inside fixed windows, avoiding length-matching bias and preserving semantic consistency between behavior and trajectory.
🪜 Two Training Stages
Stage I aligns the diffusion backbone to the driving domain using about 145k driving-related QA pairs from existing datasets, grounding perception and prediction in realistic scenes.
Stage II supervises structured reasoning–action pairs on nuScenes and WOD-E2E (23k + 30k samples), so that object detection, explanations, meta behaviors, and trajectories are learned to stay consistent.
Demonstration
Intersection with a stop sign at night (WOD-E2E)
Night-time intersection with a clearly visible stop sign, where
dVLM-AD produces a more stable “come to stop / go straight”
trajectory that better matches its reasoning about the traffic element than VLM-AD.
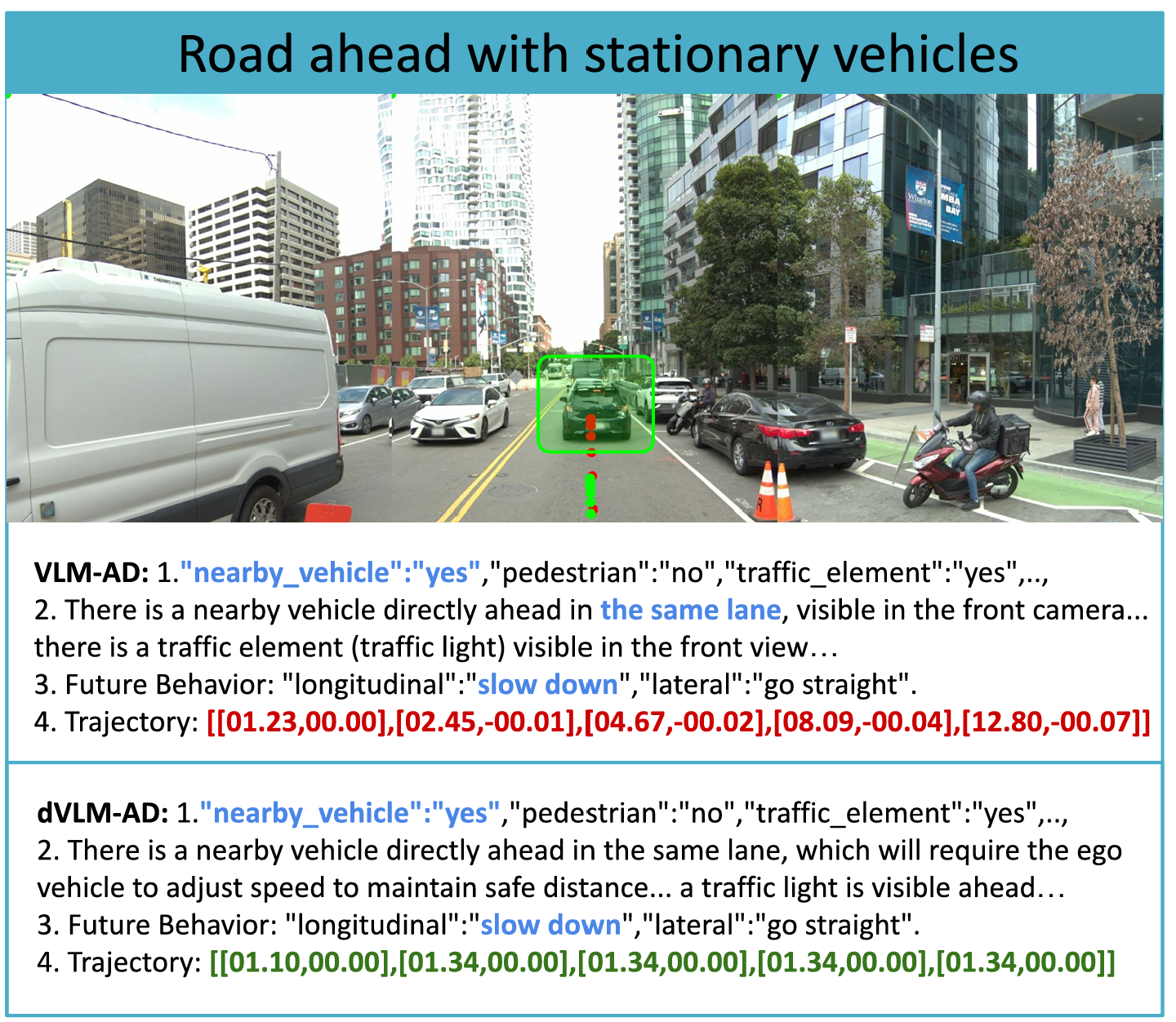
Road ahead with stationary vehicles (WOD-E2E)
Road ahead with stationary vehicles, where
dVLM-AD maintains a smoother “slow down / go straight”
trajectory that better reflects its reasoning about safe following distance than VLM-AD.
Intersection with multiple vehicles in dense fog (WOD-E2E)
Intersection with multiple vehicles in dense fog, where
dVLM-AD shows more consistent “slow down” behavior
than VLM-AD.
Downtown intersection with construction barriers (WOD-E2E)
Downtown intersection with construction barriers and a red light, where
dVLM-AD's stopping behavior at the signal is more
consistent with its textual reasoning than that of VLM-AD.
Urban intersection with multiple vehicles (WOD-E2E)
Urban intersection with multiple vehicles and stop signs, where
dVLM-AD more faithfully couples its reasoning about
stopping and following distance with the generated trajectory.
Night-time scenario with a left-turn navigation command (WOD-E2E)
Night-time scenario with a left-turn navigation command, where
dVLM-AD executes a left-turn trajectory aligned with
its reasoning, while VLM-AD behaves more conservatively.
Scenario with oncoming traffic (nuScenes)
Scenario with oncoming traffic, where
dVLM-AD's reasoning process is more accurate
and less hallucinated than the autoregressive baseline.
Driving along an open road (nuScenes)
Driving along an open road with a speed-hump marking, where
dVLM-AD's lane-following trajectory better matches its
reasoning about the clear road than VLM-AD.
BibTeX
@misc{ma2025dvlmadenhancediffusionvisionlanguagemodel,
title={dVLM-AD: Enhance Diffusion Vision-Language-Model for Driving via Controllable Reasoning},
author={Yingzi Ma and Yulong Cao and Wenhao Ding and Shuibai Zhang and Yan Wang and Boris Ivanovic and Ming Jiang and Marco Pavone and Chaowei Xiao},
year={2025},
eprint={2512.04459},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2512.04459},
}